百度图片爬虫,基于python3
个人学习开发用
单线程爬取百度图片
需要安装python版本 >= 3.6
$ python crawling.py -h
usage: crawling.py [-h] -w WORD -tp TOTAL_PAGE -sp START_PAGE
[-pp [{10,20,30,40,50,60,70,80,90,100}]] [-d DELAY]
optional arguments:
-h, --help show this help message and exit
-w WORD, --word WORD 抓取关键词
-tp TOTAL_PAGE, --total_page TOTAL_PAGE
需要抓取的总页数
-sp START_PAGE, --start_page START_PAGE
起始页数
-pp [{10,20,30,40,50,60,70,80,90,100}], --per_page [{10,20,30,40,50,60,70,80,90,100}]
每页大小
-d DELAY, --delay DELAY
抓取延时(间隔)
开始爬取图片
python crawling.py --word "美女" --total_page 10 --start_page 1 --per_page 30
另外也可以在crawling.py最后一行修改编辑查找关键字
图片默认保存在项目路径
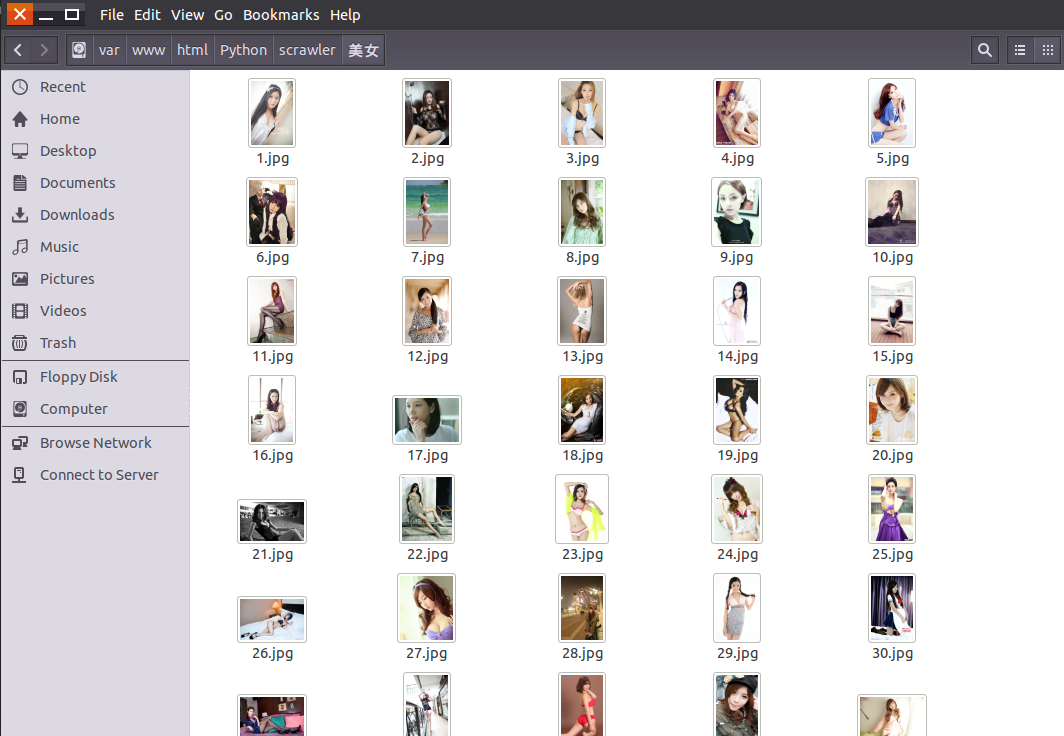
运行爬虫:
python crawling.py效果图:
您的支持是对我的最大鼓励!
谢谢你请我吃糖

